OpenLineage
An open framework for data lineage collection and analysis
Data lineage is the foundation for a new generation of powerful, context-aware data tools and best practices. OpenLineage enables consistent collection of lineage metadata, creating a deeper understanding of how data is produced and used.
QuickstartSlackGitHubAbout the Project
OpenLineage is an open platform for collection and analysis of data lineage. It tracks metadata about datasets, jobs, and runs, giving users the information required to identify the root cause of complex issues and understand the impact of changes. OpenLineage contains an open standard for lineage data collection, libraries for common languages, and integrations with data pipeline tools.

At the core of OpenLineage is a standard API for capturing lineage events. Pipeline components - like schedulers, warehouses, analysis tools, and SQL engines - can use this API to send data about runs, jobs, and datasets to a compatible OpenLineage backend for further study.
Read the javadocRead the openapi docHow to Deploy OpenLineage
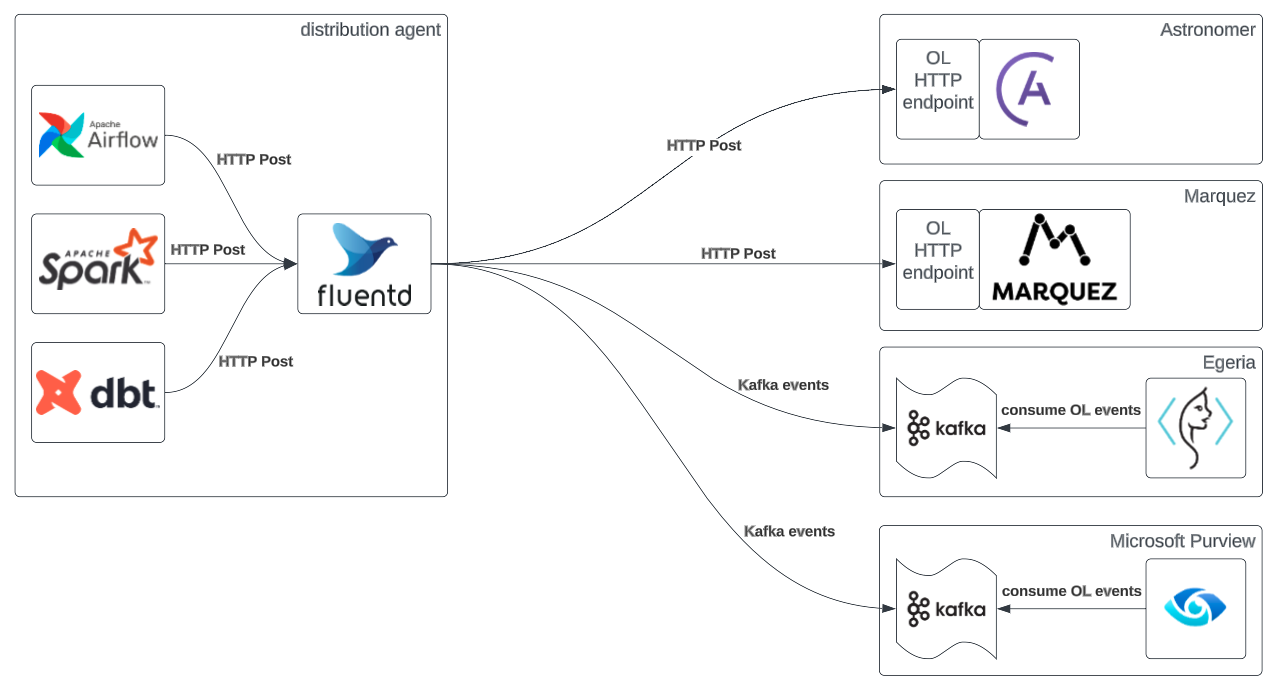
OpenLineage supports both simple deployments with single consumers and complex deployments with multiple consumers.
Simple

Complex
How to Participate
OpenLineage is an open spec, and we welcome contributions and feedback from users and vendors alike. We have a Slack community where you can engage directly with members of the project, ask questions, and share your experiences. We also run a monthly open meeting of the Technical Steering Committee where we share project updates and engage in open discussion.
TSC Meetings